
Tacotron2はGoogle社が提案した「テキストから音声に変換するアルゴリズム」です。
論文発表は2017年。しかし、2020年11月現在でも、その生成音声は最高水準の品質です。
下記にその生成音声を載せておきます。肉声と違いがわからないかもしれません。
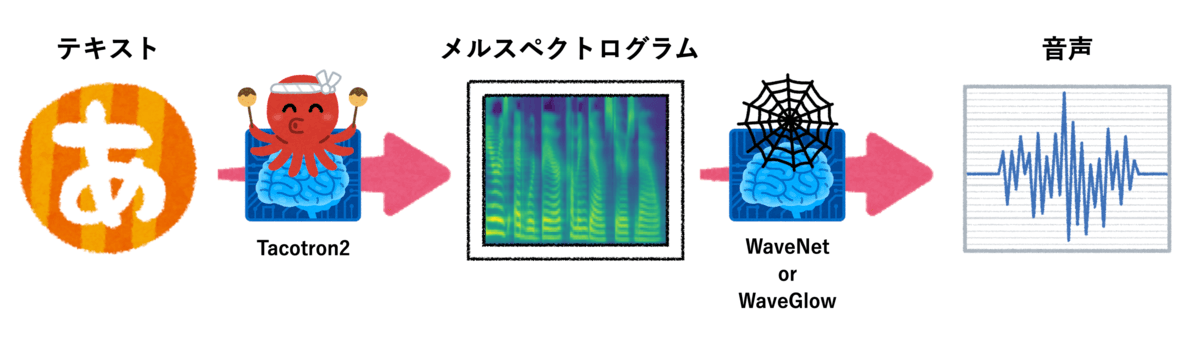
Tacotron2を使ってテキストを音声に変換する場合は「テキストからメルスペクトログラムへの変換」のあとに「メルスペクトログラムから音声への変換」を行います。
メルスペクトログラムとは、とてもざっくり説明すると声の設計図のようなものです。
Tacotron2は「テキストからメルスペクトログラムへの変換」のみを行います。
「メルスペクトログラムから音声への変換」は、Tacotron2の論文ではWaveNet、NVIDIA社のソースコードではWaveGlowというアルゴリズムを用いています。
WaveGlowは、WaveNetの処理を軽量化したものです。
Tacotron2のアルゴリズムはGoogle社から提案されましたが、その実装ソースコードはNVIDIA社が公開しています。
以下より、NVIDIA社のTacotron2+WaveGlowのソースコードをダウンロード可能です。
ただし、ソースコードの実行にはNVIDIA社のGPUが必要です。
GPUを持っていなくても、Tacotron2はクラウドでのコード実行環境「Google Colab(無料)」で実行することが可能です。手順は以下の通りです。
- 下記のリンクにアクセスする
- タブの「編集→ノートブック」でハードウェアアクセラレータをGPUに変更
- 上から順番にコードを実行する
- コード内のtext変数の値を変えることで好きな言葉での音声生成が可能
※ 現在(2021/06/12)、アップデートなどが原因で上記のGoogle Colab Notebookが動作しないようです。応急処置ではありますがpreprocessing部分の内容を以下のように置き換えると動かすことができました。ただ、こちらの置き換えも今後のアップデートによっては動かなくなる可能性もあるのでご注意ください。
# preprocessing
!git clone https://github.com/NVIDIA/tacotron2.git
%cd /content/tacotron2
from text import text_to_sequence
import numpy as np
sequence = np.array(text_to_sequence(text, ['english_cleaners']))[None, :]
sequence = torch.from_numpy(sequence).to(device='cuda', dtype=torch.int64)
input_lengths = np.array([len(sequence[0])])
input_lengths = torch.from_numpy(input_lengths).to(device='cuda', dtype=torch.int64)
# run the models
with torch.no_grad():
mel, _, _ = tacotron2.infer(sequence, input_lengths)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 22050Tacotron2の学習に必要なものは音声ファイルと、それに対応するテキストのみです。
下記のリンクのように音声ファイルのパスとテキストをまとめたファイルで指定します。
好きな声の音声ファイルでTacotron2を学習させれば、その声質のTacotron2が作れます。
下記の動画は、私が作ったTacotron2に話させたものです。
ちなみに、WaveGlowはNVIDIA社公開のモデルを使い、自分で学習させていません。
「メルスペクトログラムから音声への変換」は非話者依存なので、好きな声に変えたいという目的においては、再学習の必要はありません。
Tacotron2は入力にイントネーションの情報がないため、イントネーションが安定しないことがあります。
今後は、このイントネーションをどう安定させるかが課題ですね。

