
2025-12-27
COEIROINK投稿祭2025の感想

2025-09-22
最近作った動画についての感想

2025-07-06
カナタメモリーズ〜各EDの行き方(できるだけ内容のネタバレはなしで)〜
2025-02-24
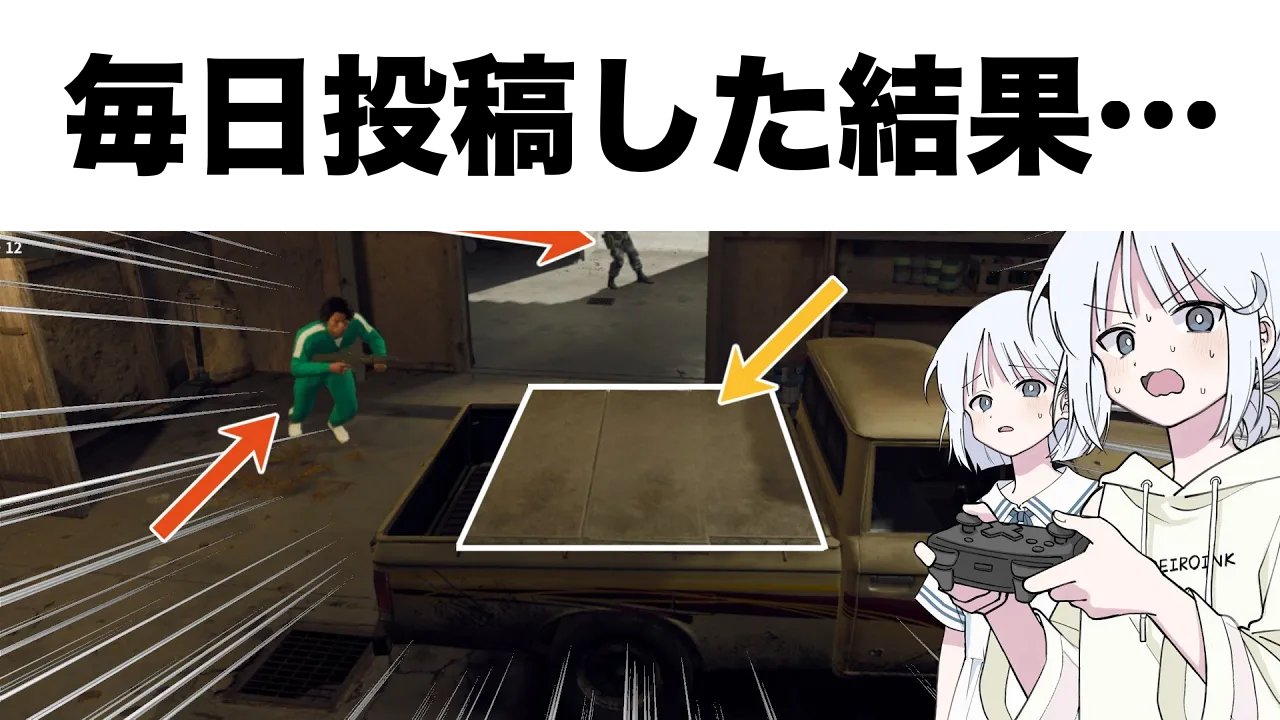
毎日投稿をやってみた結果

2025-01-26
システムメンテちゃんって誰?
2024-06-16
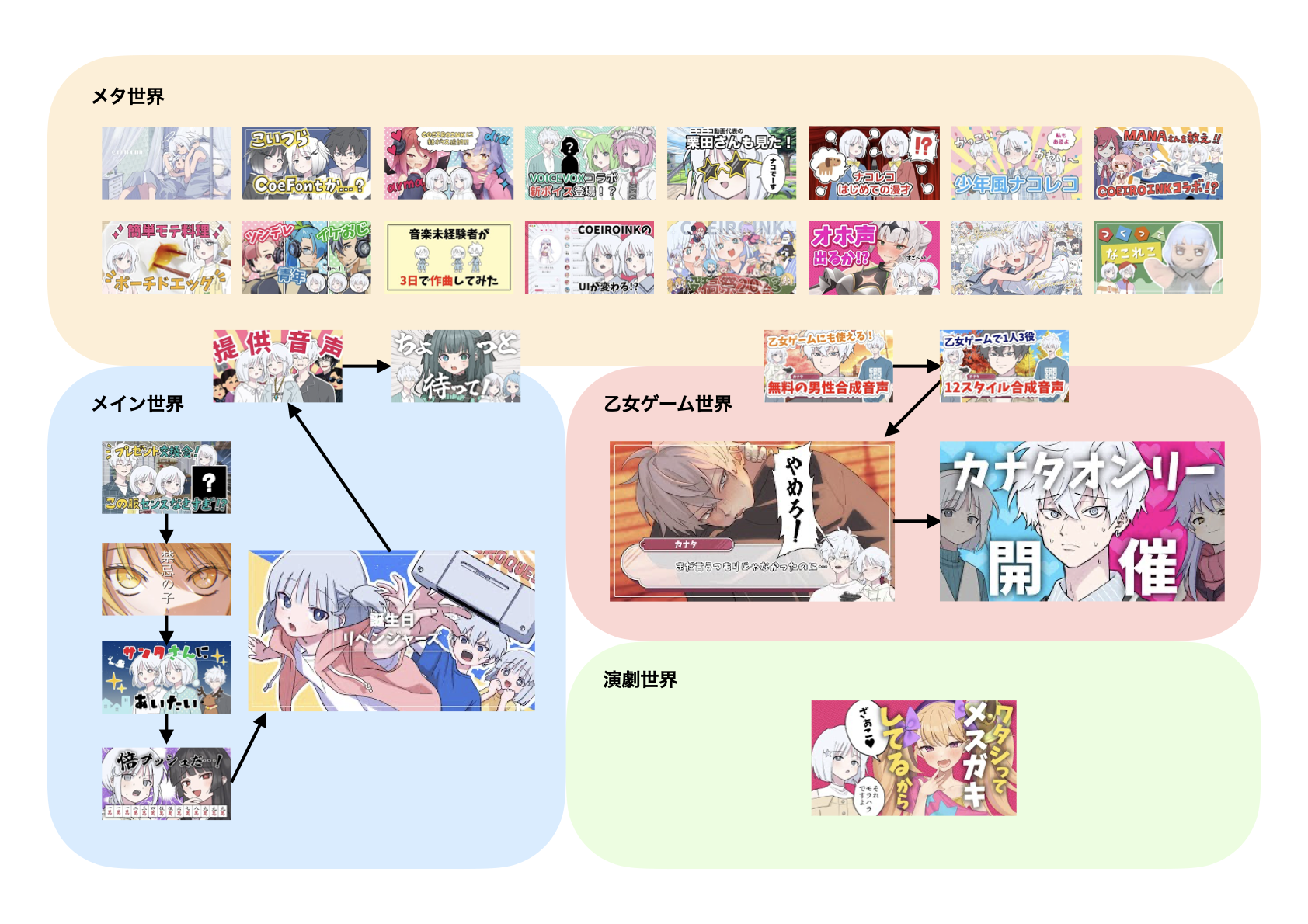
COEIROINK劇場の時系列と世界線

2024-02-25
2月月報〜コエイロプロポーズの感想〜
2024-01-16
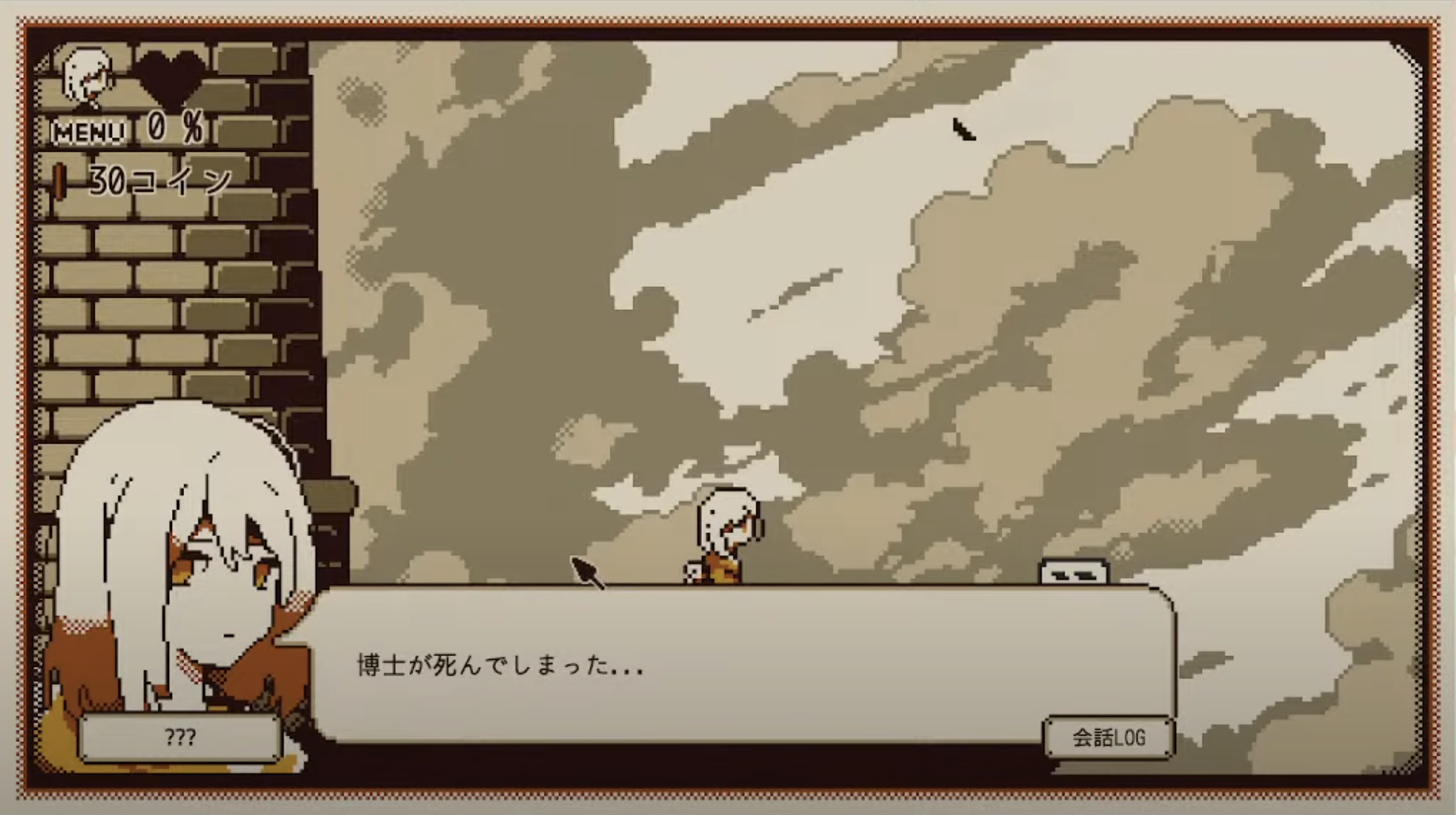
クリア後に読むことで「Refind Self」が100倍楽しくなる考察

2023-12-31
12月月報〜年納め〜

2023-11-30
11月月報〜COEIROINK投稿祭の感想〜

2023-10-31
2023年の10月月報〜配信の感想〜

2023-09-27
2023年の9月上旬月報〜COEIROINK投稿祭開催!!〜

2023-09-13
2023年の9月上旬月報〜COEIROINKは終わる!?〜

2023-09-04
2023年の8月月報

2023-02-15
COEIROINK裏話〜ナコレコの性格がもともとの予定と大きく変わった話〜

2023-02-12
ブログを書いて収益をあげた〜い!

2021-11-20
無料AIトークソフトCOEIROINKのリリース

