
Tacotron2に関しては以下の記事で説明しています。
- NVIDIA/tacotron2ソースコードの説明に従いモデルを作成し、NVIDIA提供モデルと同じモデルが作れるのかを明らかにする。
- Tacotron2のクオリティに必要な学習数を明らかにする。
NVIDIA提供モデルで使用していたデータセットはLJ Speech datasetという、英語のスピーチを13100個のwavファイルで提供しているものです。以下からダウンロード可能です。
サンプルデータとして1つ載せておきます。
"Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition
NVIDIA/tacotron2では以下の割合でデータセットをtrain、val、testに分割しています。
| 分割 | サンプル点数 |
|---|---|
| train | 12500 |
| val | 100 |
| test | 500 |
NVIDIA/tacotron2のハイパーパラメータはhprams.pyで管理されています。今回は何も修正せずに学習してみます。
NVIDIA/tacotron2ではstep数とepoch数は以下のように扱われています。設定ではepoch数のみ指定し、step数はepoch数から決まります。
| 項目 | 説明 |
|---|---|
| step | 重みの更新を行った回数。デフォルトのbach_size=64の場合、64サンプル点ごとに重みを更新するため、1stepは64サンプル分学習する。 |
| epoch | trainサンプルを何周したか。trainサンプル点数12500でbach_size=64の場合は、約195stepでtrainサンプルを一周するため、1epochは約195stepとなる。 |
デフォルトの設定では500epochでstep数は約97500stepとなります。
500epochの学習時間は、GPU RTX3090でだいたい3日〜4日くらいです。
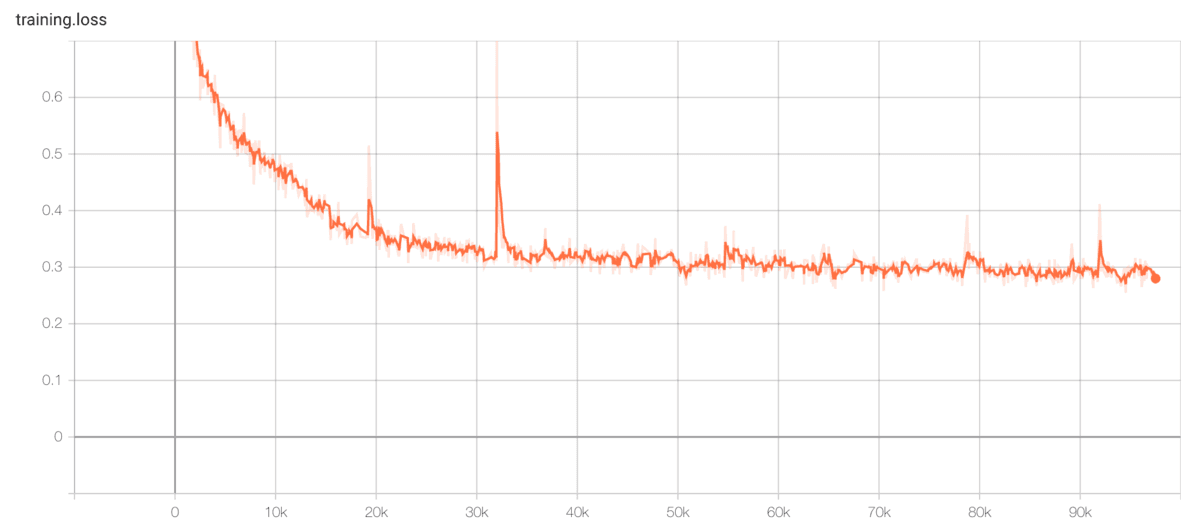
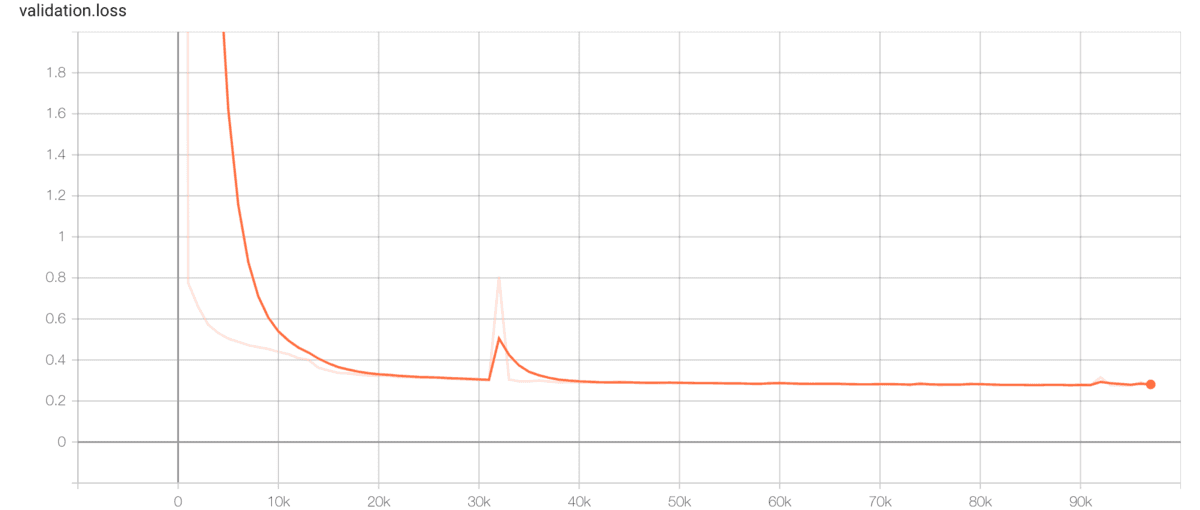
trainingとvalidationのlossを確認してみます。横軸がstep、縦軸がlossです。
グラフを確認すると、lossは約0.3あたりで減少しなくなっているように見えます。そのため、50k step(256epoch)程度で十分学習しているように思えます。
各stepのモデルでテキストから音声生成を行い、クオリティを確認します。
読み上げるテキストは「くまのプーさん」の原作「Winnie-the-Pooh」の以下の一節にします。
"Here is Edward Bear, coming downstairs now, bump, bump, bump, on the back of his head, behind Christopher Robin."
各stepモデルでの生成音声、メルスペクトグラム、アライメントを載せます。アライメントはテキストとメルスペクトグラムの対応を示しています。アライメントが綺麗な右肩上がりになっている場合は、対応が問題なく行われていることが確認できます。
step 10k
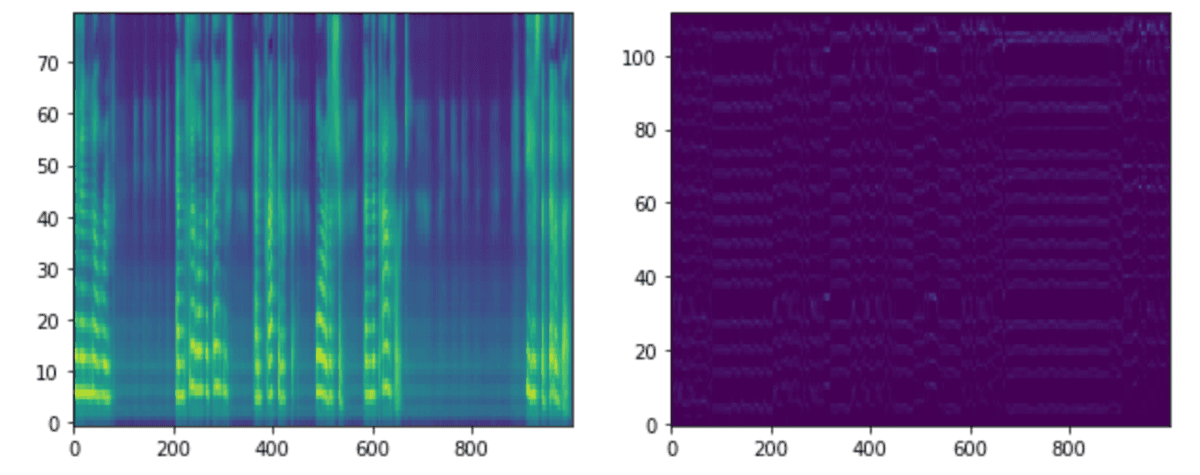
step 20k
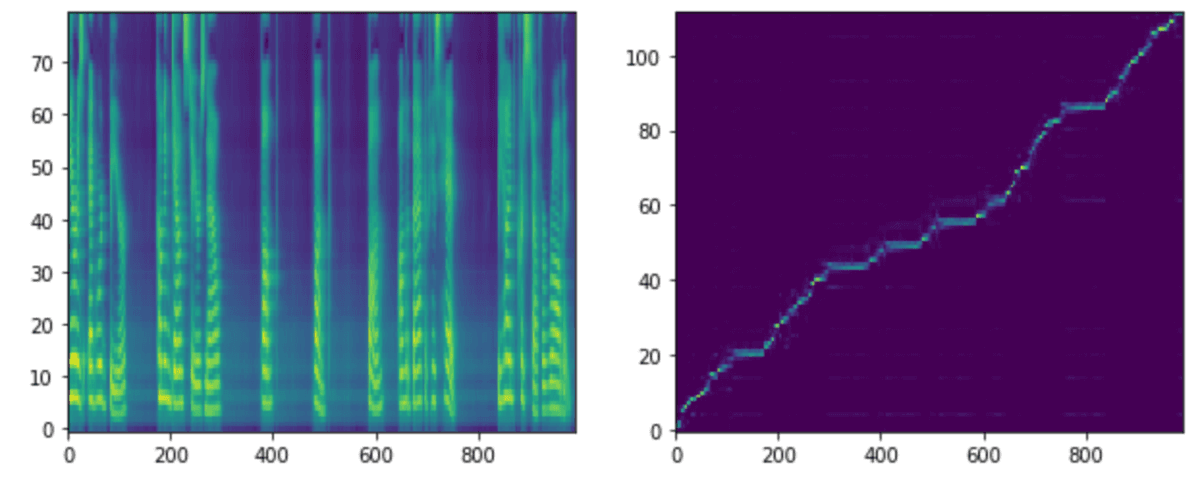
step 30k
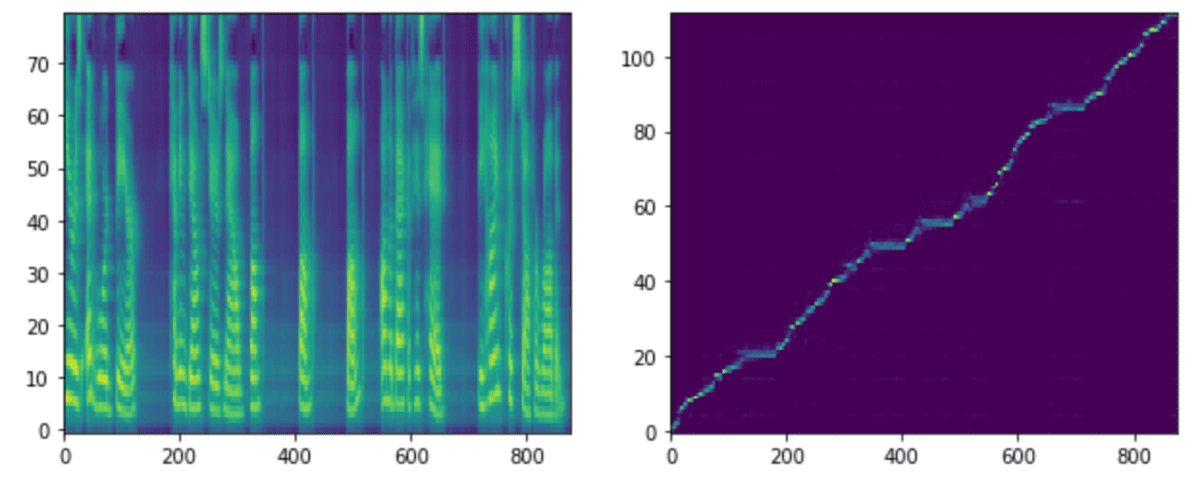
step 50k
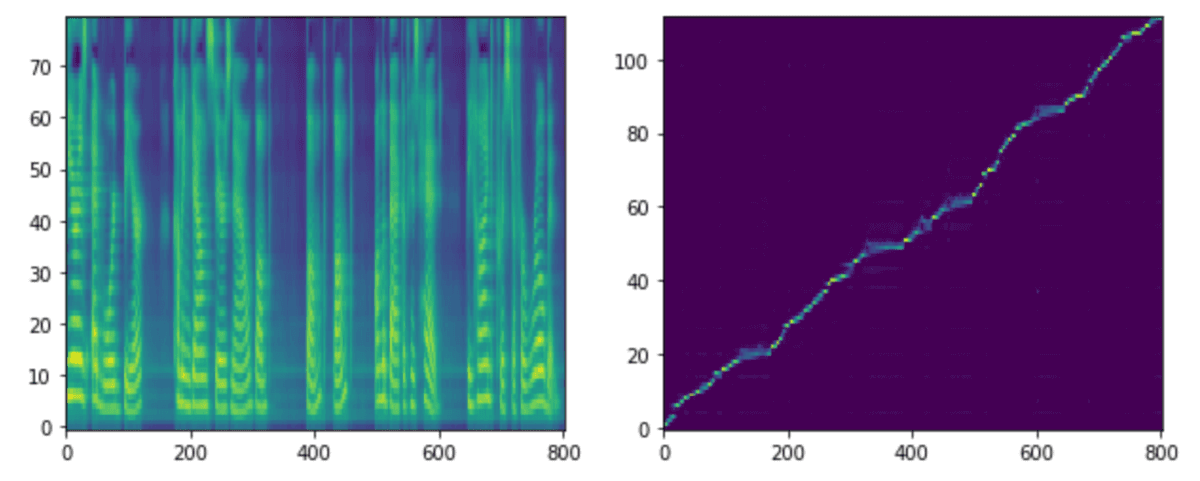
step 90k
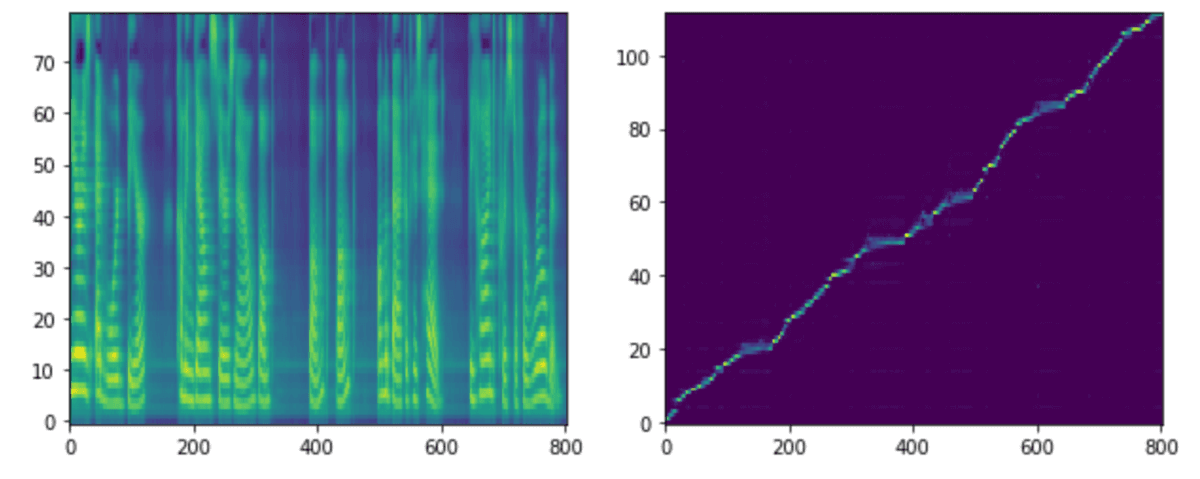
NVIDIA提供モデル
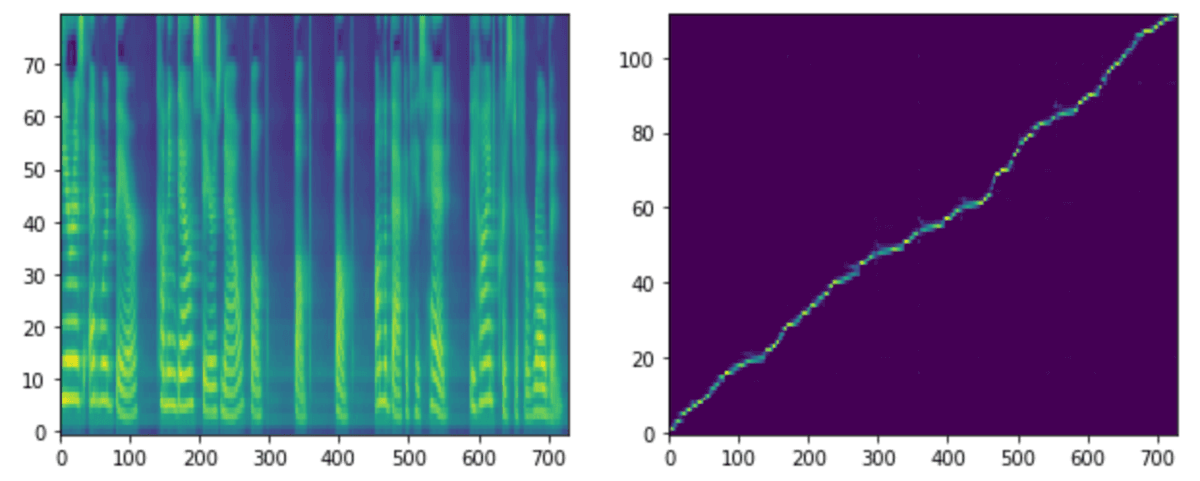
step 10kではアライメントが上手くできておらず、生成された音声も不安定です。
step 20k、30kあたりから生成音声としては問題なさそうですが、まだ安定していない印象もあります。
step 50kからはNVIDIA提供モデルとあまり差がなさそうです。
- NVIDIA/tacotron2ソースコードの説明に従いモデルを作成すると、NVIDIA提供のモデルとほぼ同じモデルが作れた。
- Tacotron2のクオリティに必要なstepは50k(256epoch)で十分そう。ただし、これはtrainデータセットのサンプル点数、batch_sizeに応じて変わる。

