
NVIDIA社が公開しているTacotron2は英語モデルです。
そのため、今回は自分でTacotron2の日本語モデルを作ってみようと思いました。
ちなみに、先に言ってしまうと今回の設定は上手く行きませんでした。上手くいったパターンは以下の「Tacotron2を日本語で学習してみる(転移学習編)」で記述しています。
Tacotron2に関する説明は以下で行っています。
以下の音声データセットで日本語のTacotron2を作成してみようと思います。
これは、夏目漱石の明暗を朗読したデータセットで、6841個のwavファイルで構成されています。音声データの中身を、例として載せておきます。
tacotron2で学習するためにはwavファイルとテキストの対応を示すfilelistを作る必要があります。そのため、データセットに含まれていたtextからtacotron2用のfilelistを作成しました。
meian/meian_0000.wav|この前探った時は、途中に瘢痕の隆起があったので、ついそこが行きどまりだとばかり思って、ああ云ったんですが、|kono mae sagut ta toki wa 、 tochu- ni hankon no ryu-ki ga at ta node 、 tsui soko ga yukidomari da to bakari omot te 、 a- yut ta n desu ga 、|8.77
meian/meian_0001.wav|今日疎通を好くするために、そいつをがりがり掻き落して見ると、まだ奥があるんです」|kyo- sotsu- wo yoku suru tame ni 、 soitsu wo garigari kaki otoshi te miru to 、 mada oku ga aru n desu|7.48meian/meian_0000.wav|konomaesaguttatokiwa,tochu-nihankonnoryu-kigaattanode,tsuisokogayukidomaridatobakariomotte,a-yuttandesuga,
meian/meian_0001.wav|kyo-sotsu-woyokusurutameni,soitsuwogarigarikakiotoshitemiruto,madaokugaarundesu音素の変換は行わなくても学習できるかもしれませんが、私は以下のように一部音素を変換しました。
| 変換前 | 変換後 |
|---|---|
| 、 | , |
| 。 | . |
| ' | n |
| ―― | <削除> |
| ? | <削除> |
| ? | <削除> |
| <半角空白> | <削除> |
データセットのwavファイルはサンプリングビットが32なのですが、このままでは上手く学習できなかったため、サンプリングビットを16に変換しました。サンプリングビットの変換方法については以下で説明しています。
データセットはtrainとvalを以下のように分割しました。
| 項目 | 数 |
|---|---|
| train | 6800 |
| val | 41 |
日本語で学習するにあたり、以下のハイパーパラメータを変更しました。text_cleanersは、今回はローマ字で音素を示すためbasic_cleanersに変更、batch_sizeは、GPUのメモリが足りなかったので32にしました。
| 項目 | デフォルト値 | 設定値 |
|---|---|---|
| text_cleaners | ['english_cleaners'] | ['basic_cleaners'] |
| batch_size | 64 | 32 |
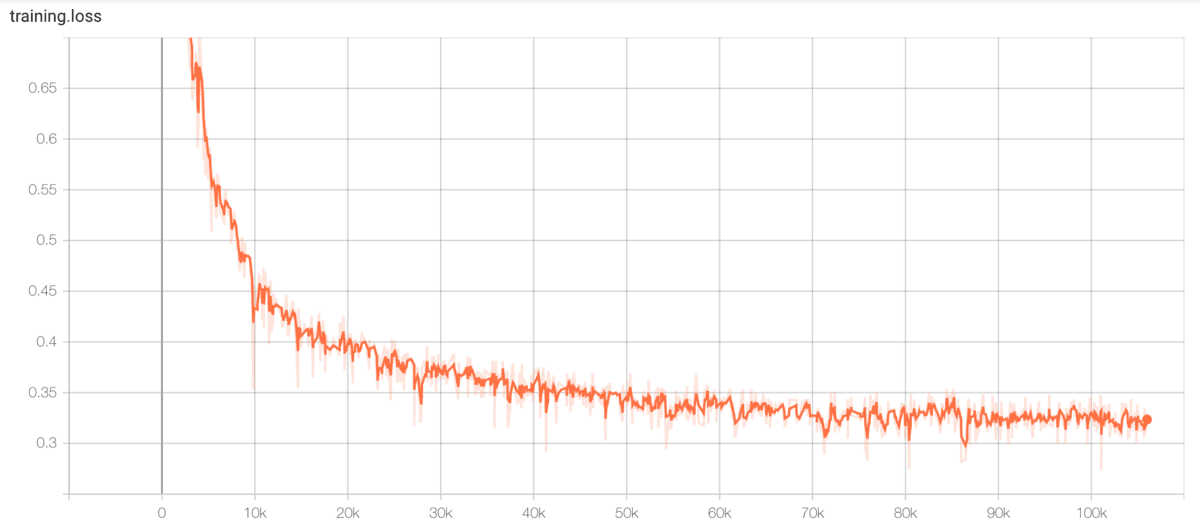
trainのlossの結果です。0.325ぐらいで収束しています。
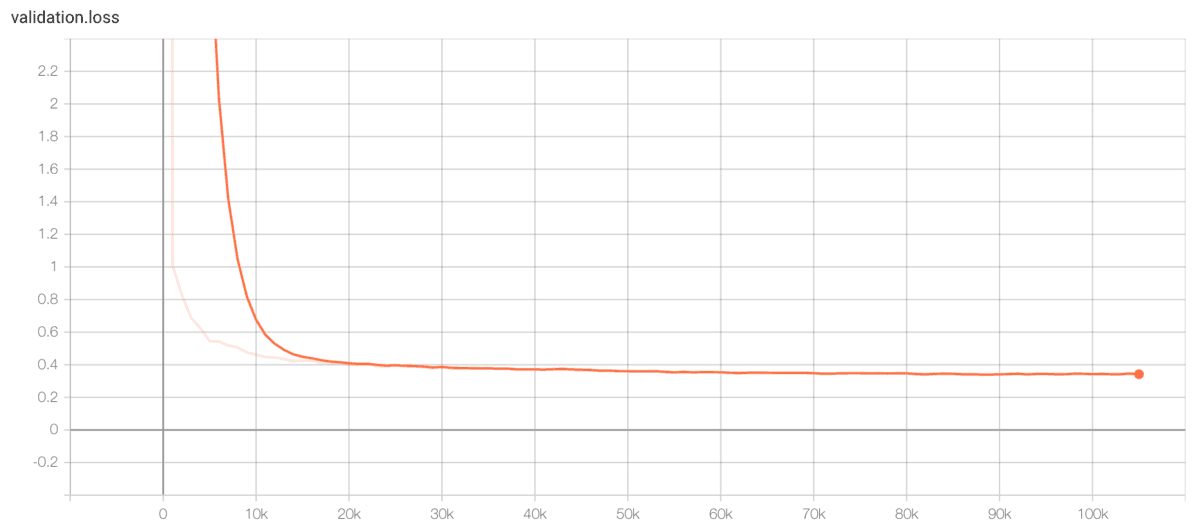
valのlossの結果です。これも収束していそうです。
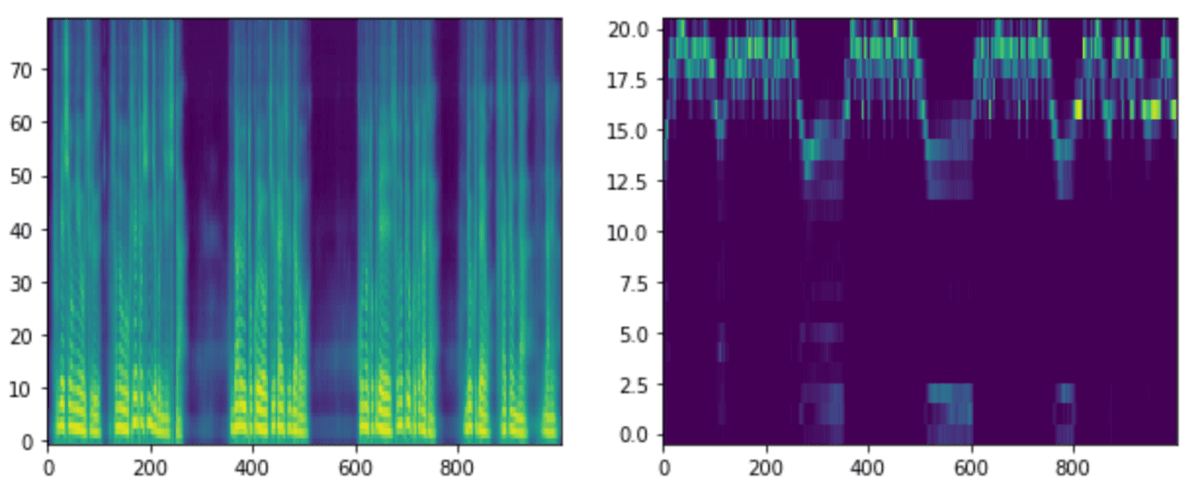
学習は上手くできていたように思えましたが、意外にも音声生成結果は散々なものでした。以下は「今日はいい天気ですね」で音声生成したときのメルスペクトグラムとアライメントです。アライメントはテキストとメルスペクトグラムの対応を示していますが、上手く対応付けできていないことがわかります。
原因はデータセット 、ハイパーパラメータと色々考えられますが、今回は細かく調査しないことにします。理由は、次に英語モデルを初期値とした転移学習を試した結果、そちらでは上手く音声生成できたからです。
日本語音声データセットを用いて、0からTacotron2を学習してみたのですが、データセット 、または、ハイパーパラメータの影響で上手く音声生成できませんでした。
しかし、この後に英語モデルを初期値とした転移学習では、上手く音声生成できました。内容については、以下の「Tacotron2を日本語で学習してみる(転移学習編)」を参照してください。

