
NVIDIA社が公開しているTacotron2は英語モデルです。そのため、今回は自分でTacotron2の日本語モデルを作ってみようと思いました。そこで、前回は日本語のデータセットを準備し、0からTacotron2の学習を行ってみたのですが、データセット 、または、ハイパーパラメータの影響で上手く音声生成できませんでした。そのため、今回は英語モデルの重みを初期値とした転移学習で試してみたいと思います。
Tacotron2に関する説明は以下で行っています。
以下の設定は前回の記事と同じです。前回の記事を参照してください。
- データセットの前処理とtrainとvalの分割
- Tacotron2のハイパーパラメータ
NVIDIAのTacotron2は、学習時に「-c モデルのパス --warm_start」とオプションをつけることで、パスで指定したモデルの重みを初期値として学習を行うことができます。今回は、NVIDIA社が公開しているTacotron2の英語モデルを初期値に指定して学習を行ってみます。
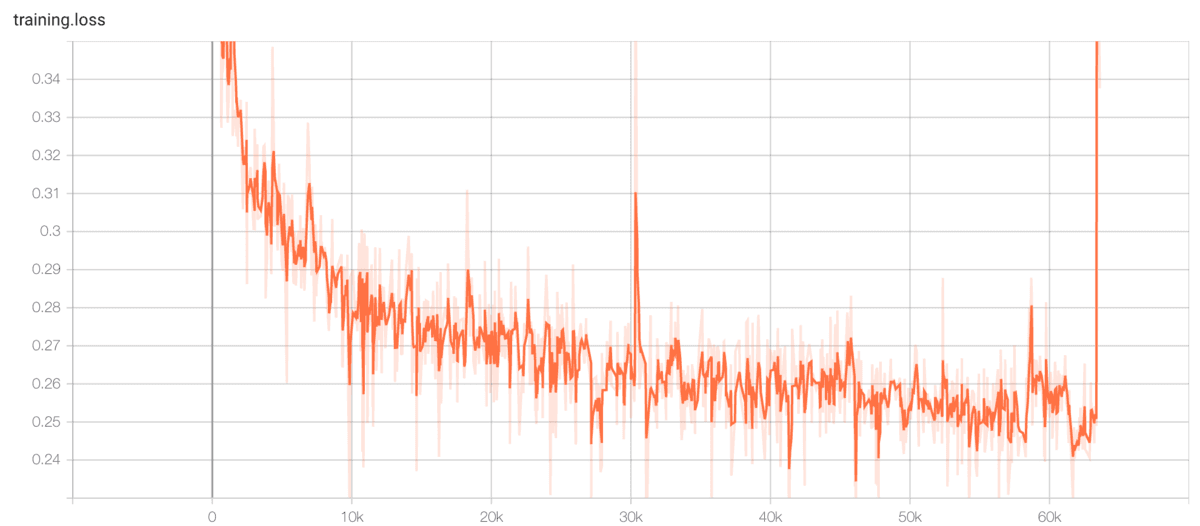
$ python train.py --output_directory=outdir --log_directory=logdir -c tacotron2_statedict.pt --warm_starttrainのlossの結果です。0.25ぐらいで収束しています。0から学習時は0.325ぐらいで収束していたので、lossの値は小さくなっています。
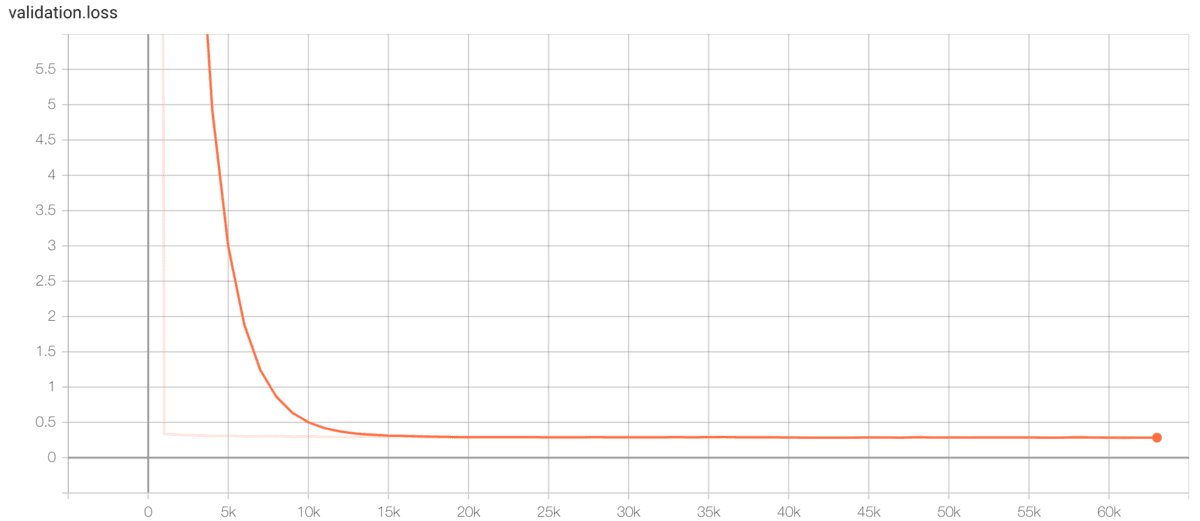
valのlossの結果です。これも収束していそうです。
各stepのモデルでテキストから音声生成を行い、クオリティを確認します。
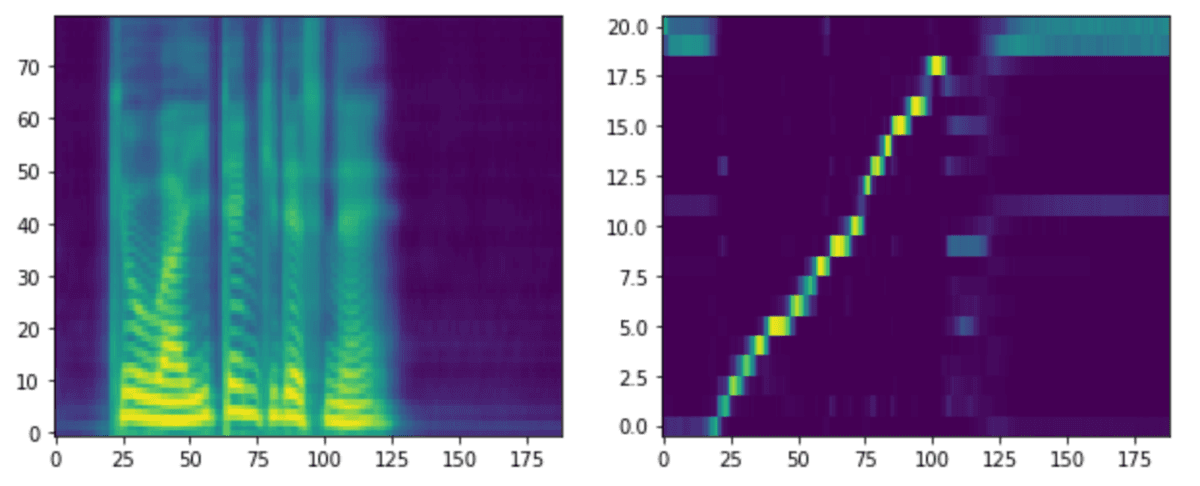
読み上げるテキストは「今日はいい天気ですね」にします。各stepモデルでの生成音声、メルスペクトグラム、アライメントを載せます。
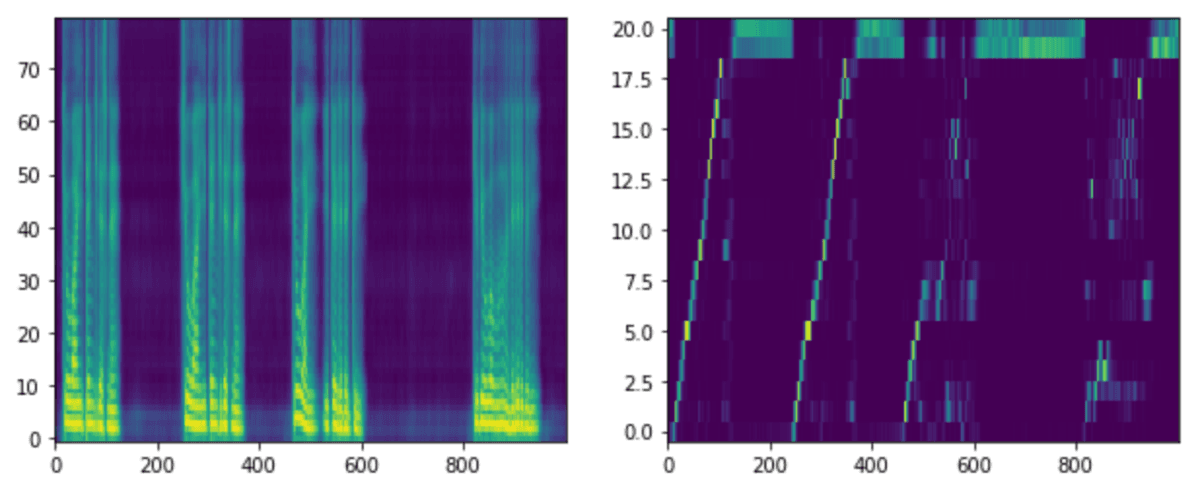
アライメントはテキストとメルスペクトグラムの対応を示しています。アライメントが綺麗な右肩上がりになっている場合は、対応が問題なく行われていることが確認できます。
アライメントをみる限り上手く対応できていないように見えます。生成音声を聞いてみるとなぜか「今日はいい天気ですね」を繰り返していました。音声の終わりが上手く予測できていないだけで、「今日はいい天気ですね」という音声は聞き取れました。
Tacotron2は生成のたびに、メルスペクトログラムが変わるのですが、step 20kでは、1/2ぐらいの割合で「step 10kのときのように失敗」となり、1/2ぐらいの割合で「以下のようにちゃんとした聞ける音声」となりました。1/2の成功では、サービスとしては提供できなさそうですが、個人で使う分には「上手く生成できたもののみを使う」ということはできそうです。
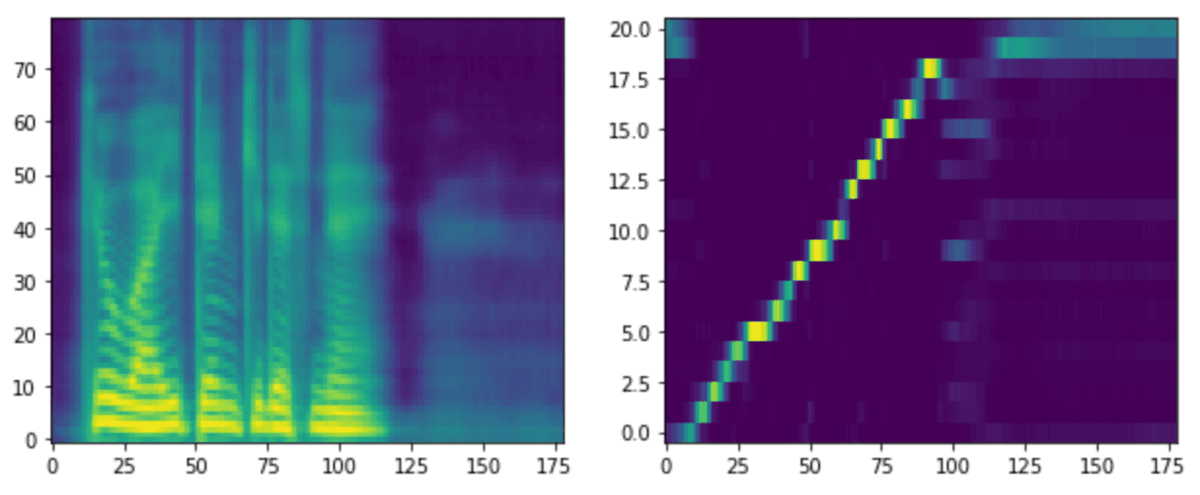
なぜか生成失敗率が上がりました。4/5ぐらいの割合で「step 10kのときのように失敗」、1/5ぐらいの割合で「以下のようにちゃんとした聞ける音声」となりました。なぜ失敗率が上がったのかは謎です。
Tacotron2では転移学習が良い効果をもたらすことが多いようです。今回の実験でも、0からの学習では生成できなかった「ちゃんとした聞ける音声」が転移学習では生成できました。ただし、安定した音声を常に生成できないという問題はありました。これは予想ですが、データセットの音声がTacotron2の安定に関係しているように思います。「滑舌良く抑揚の少ない音声データセット」の方がTacotron2の予測は安定するように思います。

