
以下のような、アニメ風の合成音声を自作する方法を記述します。
「今日はいい天気ですね。」
今回はTacotron2という技術を使いました。Tacotron2に関しては以下で説明しています。
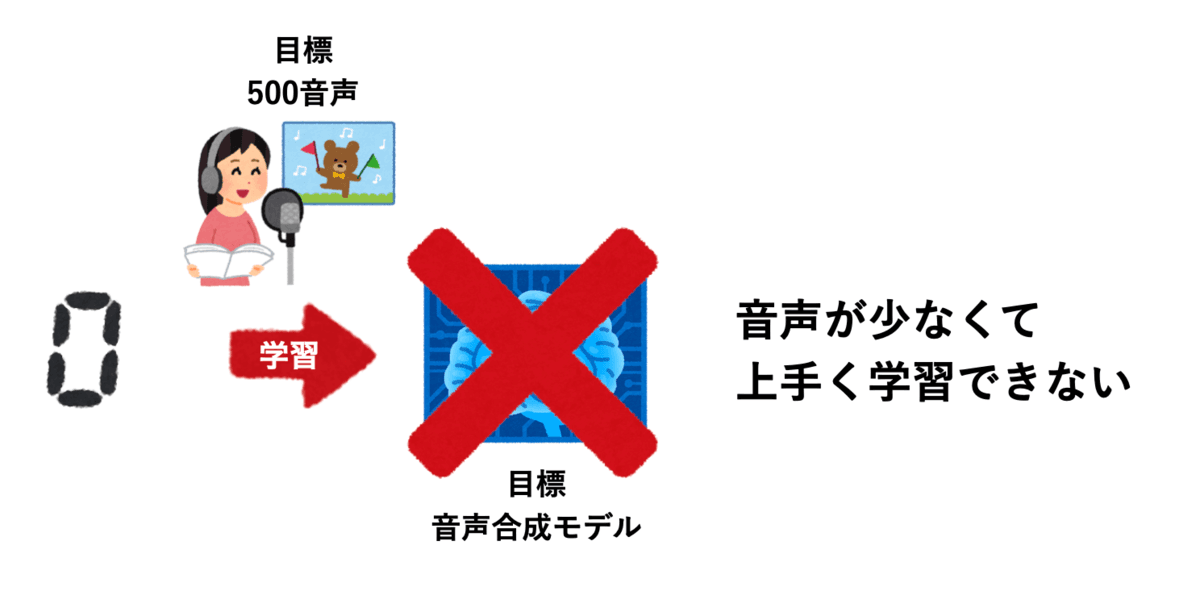
学習のために、アニメ風の音声を535用意しまいした。そのうち500を訓練、35を検証に分割しています。
| 項目 | 数 |
|---|---|
| train | 500 |
| val | 35 |
Tacotron2を0から学習させようとすると、5000程度の音声を必要とするように思います(筆者の体感)。しかし、目標とする音声を5000も集めることは困難です。そこで今回は転移学習という技術を使いました。
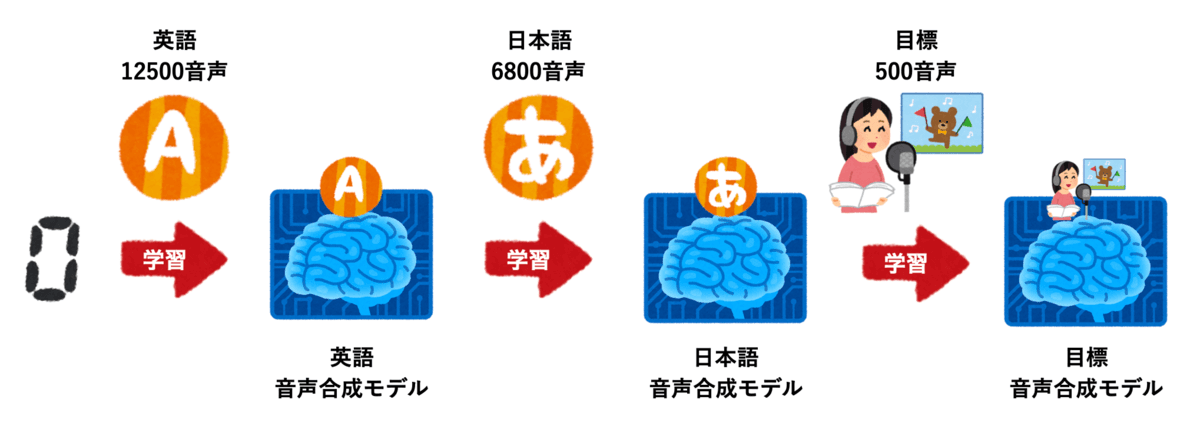
転移学習は簡単に言えば、目標の音声以外で学習して音声合成モデルの基礎を作り、目標音声で追加学習して目標の声のモデルを作るという発想です。
今回はパブリックドメイン(著作権なし)の音声のみで基礎を作ろうとしたため、12500の英語音声で学習したあと、6800の日本語音声で学習することで、日本語の基礎モデルを作っています。具体的なこの基礎モデルの作り方に関しては以下の記事に記述しています。日本語の音声をたくさん持っているのであれば英語モデルを経由せず、いきなり日本語音声で基礎モデルを作成しても良いと思います。
学習時のハイパーパラメータは、500とサンプル点数が少ないので、batch_sizeを10にしました。
| 項目 | デフォルト値 | 設定値 |
|---|---|---|
| text_cleaners | ['english_cleaners'] | ['basic_cleaners'] |
| batch_size | 64 | 10 |
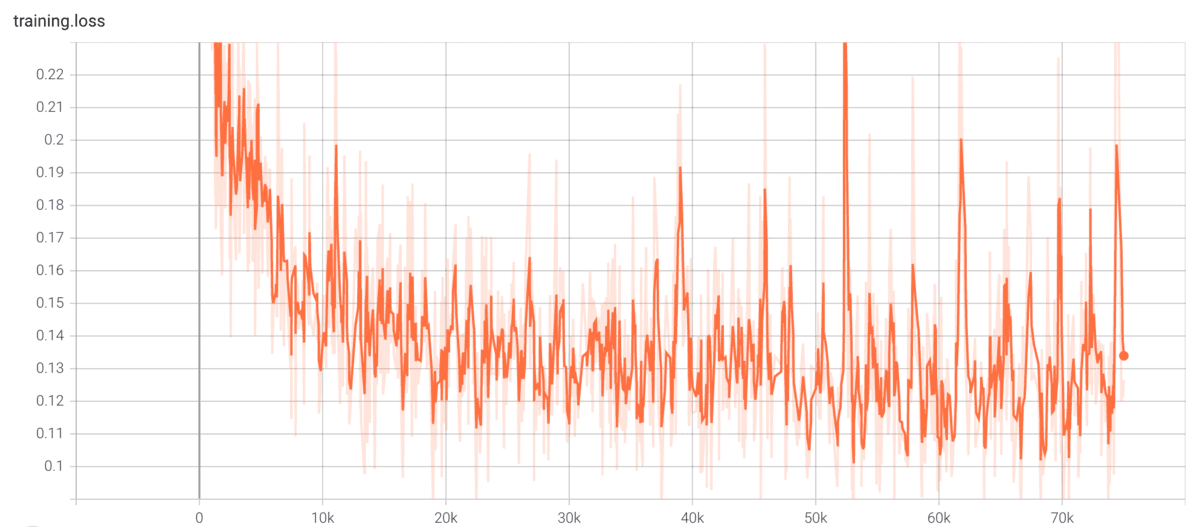
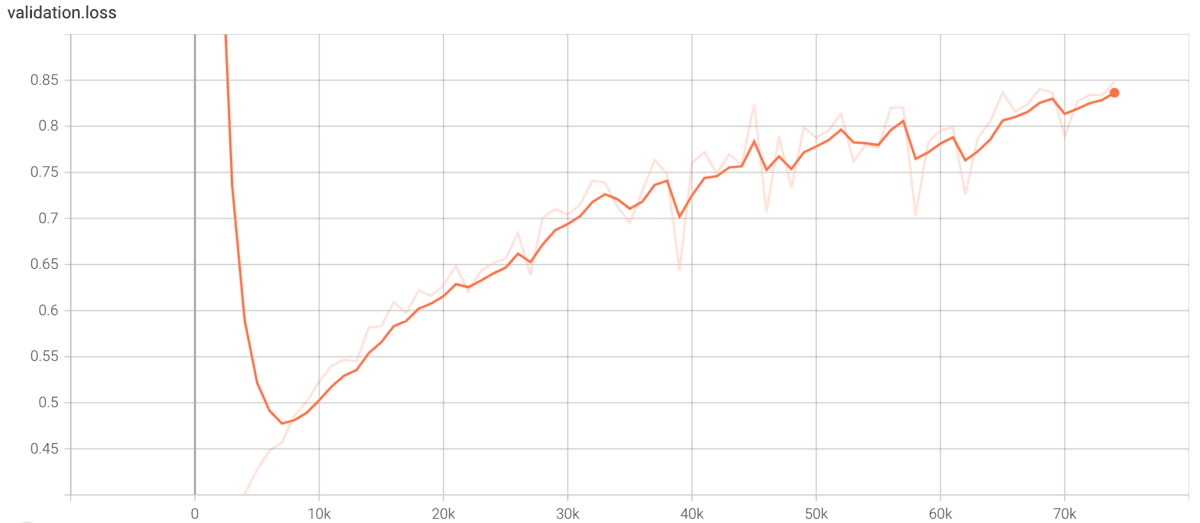
学習後のtrainとvalのlossの結果です。valが途中から右肩上りになっているので、過学習しているようにも思います。しかし、生成音声のクオリティに関してはvalの最小点あたりの、7k stepと74k stepであまり差を感じませんでした。過学習ではなくvalの音声が35と少ないことが原因なのかもしれません。
74k stepでの生成音声をいくつかのせておきます。綺麗に生成できないことも多いですが、以下のようなアニメ風の合成音声を作ることに成功しました。
「いつもがんばってて偉いね」
「今日はメントスコカコーラをしてみようと思います」
「シロワニさんの機械学習ブログをよろしくお願いします」
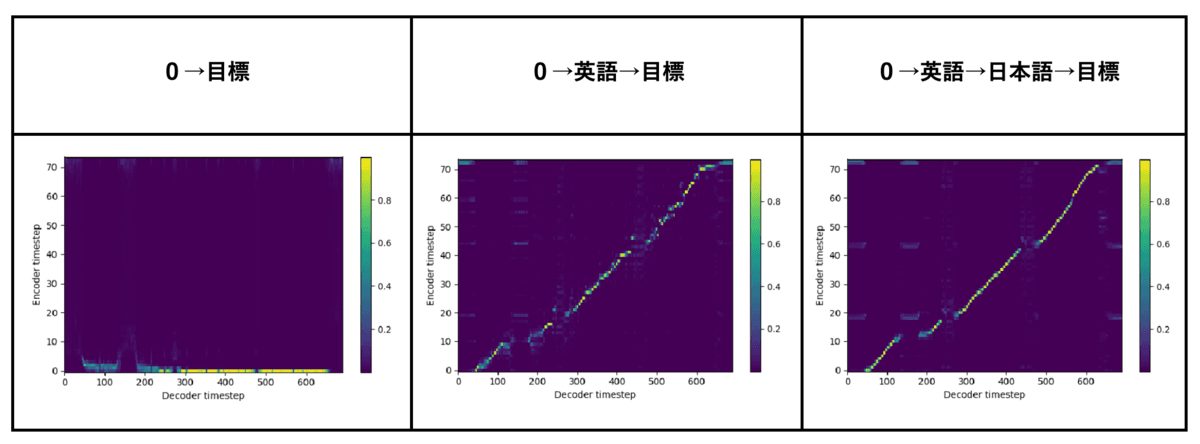
以下の図は転移学習ありなしでの生成音声のアライメント(文字と音声の対応)を表しています。アライメントが綺麗な右肩上がりを示すほど学習が上手く行われていると考えられます。図から転移学習をした方が上手く学習できていることがわかります。
以下のような動画へ活用することも可能です。今後はより人に近い合成音声の動画が増えていくかもしれせんね。
今回はTacotron2を用いて、アニメ風の合成音声を自作しました。しかし、ノイズ・クオリティ・安定性の面でまだ課題があるように感じます。今後は他の技術も試してより良い音声合成を作っていこうと思っています。

