
私はアニメ風なトークソフトの実現を目指し、いくつか自作しました。そのときに感じた、音声データの良し悪しに関して記述しようと思います。ここで話すトークソフトはディープニューラルネットワーク型(Tacotron2など)を想定して話しているので、ご注意ください。また、この記事は筆者の感覚で記述しており、技術的証明はありません。
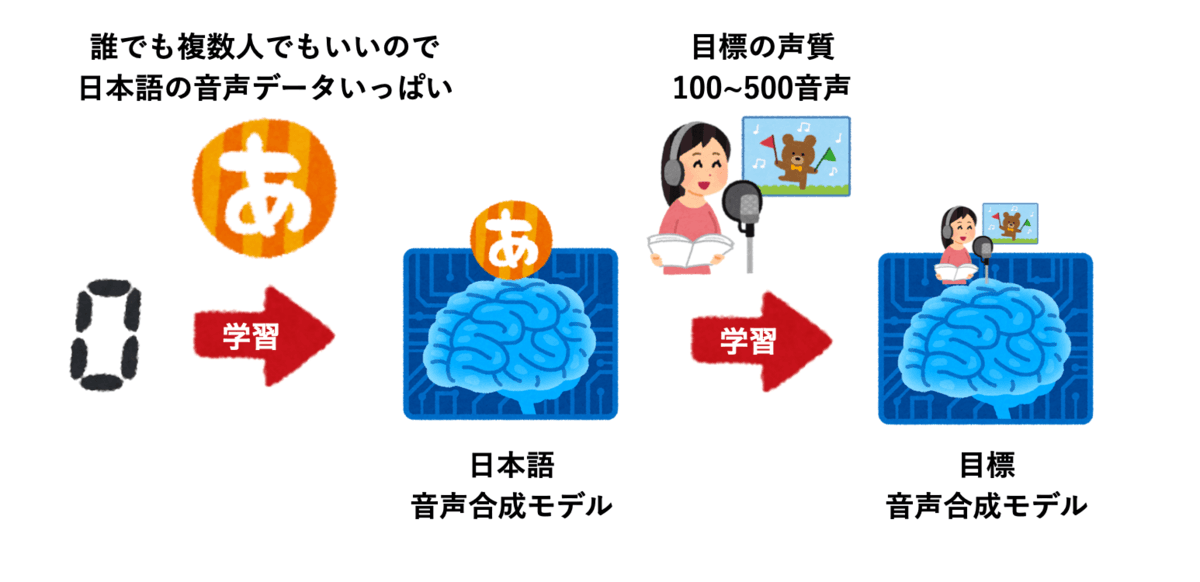
今回の記事は、目標の音声データ部分に、どのような音声データが望ましいのか記述します。
音声データは以下のような種類が考えられると思います。
- JVSなどの音声合成用の文章の読み上げ
- 小説読み上げ
- 日常会話
- アニメやゲームのセリフのような感情のこもったもの
そもそも音声合成のクオリティは何から決まるかと言うと、以下の2つから決まります。
- 抑揚と感情の幅の大きさ
- 音素が満遍なく含まれているか
「抑揚と感情の幅」が大きいほど「生成音声の安定性」は低くなり、「抑揚と感情の幅」が小さいほど「生成音声の安定性」は高くなります。
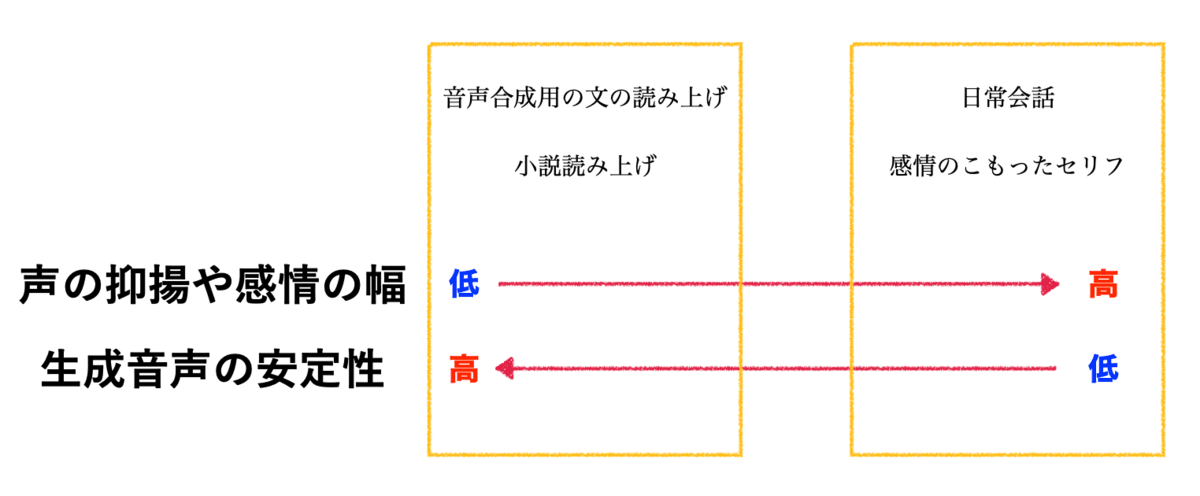
「音声合成用の文章・小説」も感情をこめて読むことができるため、文章で決まることではないかもしれませんが、「音声合成用の文章・小説」は「抑揚と感情の幅」が小さく、「日常会話・セリフ」は「抑揚と感情の幅」が大きい傾向にあります。
ただし、ここでいう感情の幅というのは、数の話であり、学習データの音声が「喜」のみならば幅は小さく、「喜怒哀楽」すべて含まれているならば幅は大きくなります。また、感情が「喜」のみであっても、抑揚が強いか弱いかで幅は変わります。
実際「抑揚と感情の幅」が小さい方が「生成音声の安定性」は高くなりますが、ナレーションのようなTTSになる傾向にあります。アニメキャラのようなTTSを作りたければ「抑揚と感情の幅」を大きくする必要があるのですが、「生成音声の安定性」が低くなるので難しいところです。
TTSでは「ら」というテキストから「ら」の音声を生成します。もちろん、学習した音声データの中に「ら」という音が一度もでてこないなら「ら」を作ることはできません。また、声というのはデリケートなもので、同じ「ら」であっても、後に続く文章によって、音としては違う「ら」だったりします。
そのため、学習する音声データはそういった音を全て網羅できていることが望ましいです。「音声合成用の文章」はそのあたりを考えて作られているので安心です。しかし、「小説・日常会話・セリフ」はここが保証できていないため、TTSにしたときに上手く言えない言葉がでてきたりするため、注意が必要です。
「小説・日常会話・セリフ」を学習する音声データとして使う場合は、「音声合成用の文章」より数が多く必要になる可能性が高いです。
学習した音声データの「抑揚と感情の幅」が大きいと「生成音声が安定しない」と記述しましたが、安定しないとはどいうことかを説明します。
例えば、音声データに同じ「みなさんこんにちは」を3種類の感情で言ったものがあったとします。
- 「みなさんこんにちは」(ふつう)
- 「みなさんこんにちは」(元気よく)
- 「みなさんこんにちは」(しょんぼり)
TTSは「みなさんこんにちは」という文字から、1つの音声を決めて生成しなくてはいけません。しかし、音声データによると、答えは3つあることになります。このとき、TTSがどのような挙動をするかというと、3つから1つをランダムに選んだり、平均的などれでもない音声になったりします。
ここで皆さんは「同じ文章を学習に加えることはないので大丈夫だ」と思うかもしれませんが、実際音声の予測は音素単位で行われます。「み」だけでも色んな感情の「み」があると、どの「み」を作ればよいのかTTSはわからなくなってしまうのです。
結果として「抑揚と感情の幅」が大きいと、生成のたびに違うイントネーションになってしまったり、正しいイントネーションの音声が生成できなくなってしまうのです。
「わぁ!」「えー!」「へー」のような感嘆詞を学習に加えた方が良いのかについても記述します。感嘆詞を学習に加えると、TTSで感嘆詞を生成することも可能になります。しかし、その代償として、他の言葉が言えなくなる可能性があります。例えば「えー!」を学習させると「AI(エーアイ)」と正しく音声生成できなくなったりします。「AI」といいたいのに「えー!アイ」で生成されちゃうんですよね。このことから、汎用的な利用を目的とするTTSでは、感嘆詞は学習に加えないことをお勧めします。
また、デープニューラルネットワーク型TTSは、その特性上、あまり短い文章の生成に向いていません。そのため、感嘆詞のみの短い音声データは除いた方が良いかもしれません(長すぎても向いてないんですけどね......)。
上記をまとめると、以下の条件を満たす音声データが良いと言うことになります。このような音声データを作ると、どんな言葉でも安定して綺麗に話してくれるTTSになるのではないかと思います。
- 各音素が満遍なくたくさん含まれる
- 感情がひとつ
- 感嘆詞がない
- 各音声が短すぎず長すぎない
- データの数が多い
- 抑揚が少ない
抑揚に関しては、アニメ風なTTSを作るために譲れない場合もあると思います。ここは、抑揚以外の条件を満たせているならば、抑揚が大きくても、まずまず綺麗に話してくれるのではないかと思います。
余談ですが、感情の幅が大きい音声データで学習させると、前後の文で感情を操作できるTTSが作れたりします。
- 「やったー、みなさんこんにちは」(「みなさんこんにちは」も元気に話す)
- 「がーん、みなさんこんにちは」(「みなさんこんにちは」もしょんぼり話す)
ただし、綺麗に操れるわけではなく、安定性は低くく、発音できない言葉も増える印象です。色んな感情で話してくれるという点ではすごく良いのですが、汎用的なTTSとして使えないイメージです。
言葉だけでなく学習した音声データの息継ぎもTTSに反映されたりします。

